
A voice recognition system can be defined as a system that translates voices received from a microphone into word clusters.
Voice Recognition Process:
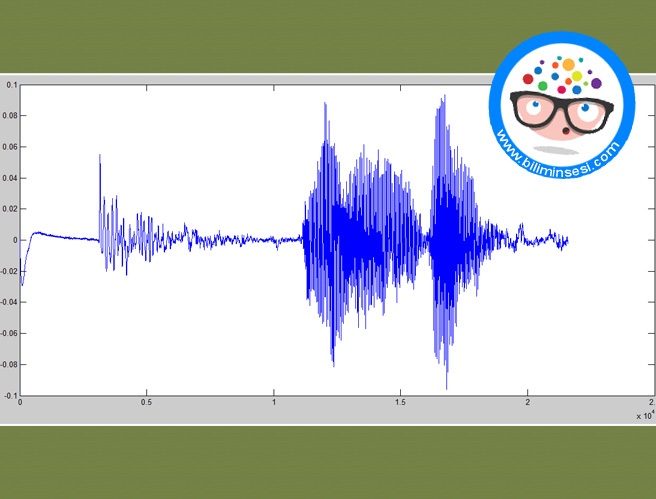
We can say that voice recording, voice processing, comparison and matching operations are in order. Voice recording; acoustic sound taken with a microphone is digitized and recorded by sampling on a computer.
The general operations are windowing, filtering, normalization and audio coding in the process of voice processing.
The structures used for comparison and pairing are as follows:
Hidden Markov Model
Voice recognition systems convert sound waves into sound vectors. These vectors are analyzed as a finite state machine according to Markov model. In this case, the next vector in the audio vector is not related to the past.
The state sequence is reserved in this model and is calculated taking into account this situation in the vectors. It is called the Hidden Markov Model and this causes some restrictions in the system. The sound signals must be symbolized for the sound signals to be processed as a finite state machine.
Before this operation the sound wave must be passed in the signal processing phase.
There are algorithms for finding the state sequence:
- The forward algorithm: Provides the order of states and the probability of the order of all states.
- Viterbi algorithm: The ideal case overlaps with the sound vectors from the state sequences.
- Baum-Welch algorithm: Computes the current probabilities by scanning the vector sequence from beginning to end.
After the voice signals are processed and separated, the resulting parts should be correlate on the existing voice and syllable. Language elements such as grammar and pronunciation should be analyzed in order to achieve this.
Once the sound signals are processed and separated into the smallest parts, these parts must be overlapped with the corresponding sound and syllable. For this, it is necessary to combine many items such as grammar, pronunciation dictionary, and word nets.
Artificial neural networks
Artificial neural networks can be trained to create a relationship between inputs and outputs. Because of this feature they are used for pattern recognition or classification purposes. In voice recognition systems, the aim is the determine words from phonemes corresponding to the voice mark. It is possible to classify the vectors corresponding to the voice mark with artificial neural networks. Artificial neural networks are used in voice recognition systems in this way.
Dynamic Time Warping
It is not always possible for a word to be pronounced by the same person all the time. The vocalization of the word can take longer than and shorter in different tries.
The Dynamic Time Warping algorithm tries to approximate these two voices by spreading or narrowing them over time. Thus, these two pronunciations overlap over time.
The DTW algorithm is a frequently used method in word-based speech recognition systems. With this approach, it is possible to perform word segmentation that is detected at the moment of operation, by comparing the vocabulary templates and the vocalization times in the system.
Uses of Voice Recognition Systems
In today World, Voice recognition systems are used in many areas. There are applications such as text dialing, voice recognition for security purposes, voice commands for the disabled person.
Voice recognition systems can also be used in areas such as define the playing music and synchronizing lyrics in a playing song.
[rwp-review id=”0″]






{kind=link}